The frontier of software development is undergoing a structural transition from static text fields to dynamic audio-native environments. On May 7, 2026, OpenAI fundamentally changed the voice agent landscape by introducing a new generation of streaming models into the Realtime API. This rollout shifts voice AI from simple, high-latency call-and-response mechanisms toward ambient interfaces that can listen, reason, transcribe, and execute systems-level tasks mid-conversation.
This expansion of agentic capability directly parallels the enterprise security frameworks established during OpenAI’s previous infrastructure releases. As voice applications gain the power to trigger complex code execution on behalf of users, they must be wrapped in the strict sandboxing environments detailed in our exploration of OpenAI’s GPT-5.5-Cyber: Designed to Think Like an Attacker, which examines the security parameters required when autonomous agents are given the latitude to execute low-refusal command pathways. For developers building at production scale, integrating these voice models requires a deep understanding of behavioral boundaries, latency optimization, and intent verification.
1. Breaking Down the Models
Instead of trying to force one giant, heavy model to handle everything at once, OpenAI split the workload across three distinct engines. Each one is built for a specific job so you don’t get lag or weird pauses when you talk.
- GPT-Realtime-2: This is the heavy lifter for conversational intelligence. It brings GPT-5-level reasoning to live speech, meaning it actually follows the flow of a normal conversation. It won’t lose track of what you said ten minutes ago; it can use background tools while you talk, and if you interrupt it mid-sentence, it handles the break naturally instead of crashing or freezing. It also has a massive 128K memory window to keep long conversations coherent.
- GPT-Realtime-Translate: This engine focuses entirely on live, mouth-to-ear translation. It takes speech from over 70 different languages and translates it into 13 output languages on the fly. The real win here is that it matches the speaker’s actual pacing, keeping up with natural speech, regional accents, and industry slang without missing the core meaning.
- GPT-Realtime-Whisper: If you just need speech turned into text instantly, this is the tool. It streams transcriptions live as words leave your mouth. Because it processes audio chunks continuously with almost zero delay, it’s built to power live captions, instant meeting summaries, or real-time logs where every second counts.
2. Emerging Archetypes in Spoken Interface Design
As developers move away from old keyboard-and-screen boundaries, enterprise deployment is consolidating around three primary voice interaction archetypes.
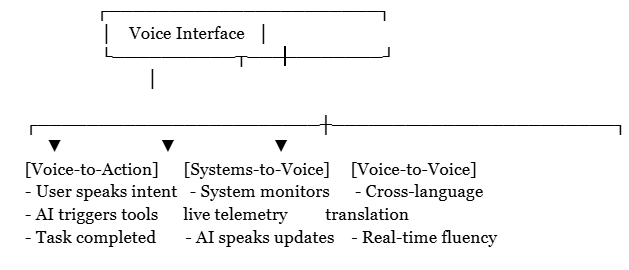
Voice-to-Action (Intent Execution)
In this pattern, the user speaks naturally to describe a complex goal, and the model orchestrates the necessary tool calls behind the scenes. For instance, real estate platforms are utilizing this to let users describe financial constraints, neighborhood preferences, and scheduling availability in a single spoken sentence, which the model instantly parses to map out weekend property tours.
Systems-to-Voice (Contextual Guidance)
This paradigm turns real-time database changes into localized spoken alerts. Instead of sending a static push notification, an enterprise application can synthesize real-time data such as flight delays or supply chain disruptions to proactively dictate alternative transit paths or mitigation steps directly into a user’s headset while they are on the move.
Voice-to-Voice (Multilingual Fluency)
This architecture allows two parties to converse naturally across language barriers. Telecom and global customer care platforms are leveraging this to let callers speak in their native regional dialects while the system translates the audio in real time with minimal word error rates, maintaining conversational momentum without artificial delays.
3. Optimizing Latency and Conversational Controls
Building a production-ready voice agent requires balancing deep reasoning with fast turn-taking. OpenAI has introduced several granular controls within the API to give developers command over this equilibrium:
- Adjustable Reasoning Effort: Developers can configure reasoning thresholds across five levels (minimal, low, medium, high, and xhigh). Simple tasks like repeating an order number utilize the low default setting to maintain sub-second latency, while logic-heavy workflows dial up the effort for deliberate, multi-step problem-solving.
- Parallel Tool Transparency: When an agent needs to access external APIs mid-sentence, it can trigger multiple tool calls simultaneously. Crucially, the model utilizes “preambles” and audible transition phrases (e.g., “Let me look that up for you” or “Checking your account now”) to eliminate dead air while the system processes the request.
- Controllable Tone Delivery: The model natively adjusts its acoustic properties based on customer context. It can project quiet confidence during professional milestone updates, maintain an empathetic cadence when handling a frustrated user, or inject excitement when confirming a successful transaction.
Deployment Framework for Developers
To get started with the new audio architectures in your development environment:
- Select Your Engine: Use GPT-Realtime-2 for interactive conversation, GPT-Realtime-Translate for multilingual pipelines, and GPT-Realtime-Whisper for streaming compliance text.
- Calibrate Latency: Set your reasoning_effort parameters to balance compute depth against user expectations, keeping simple verification tasks at the lowest latency tier.
- Enforce Disclosure Guardrails: Unless explicitly obvious from the application environment, you must implement localized prompts within your Agent SDK configuration to ensure end users are notified when they are speaking with an artificial intelligence.
Read about, Join the Elite: The OpenAI Campus Network is Building the Next Generation of AI Leader,The landscape of higher education is shifting, and it isn’t just happening in the lecture halls. On May 11, 2026, OpenAI officially opened interest for its OpenAI Campus Network, a dedicated initiative designed to empower student-led organizations with the tools and resources previously reserved for high-level tech firms.